
當人工智慧 (AI) 強勢來襲、而半導體已趨近物理極限,業界該如何因應?成立已五週年的國際半導體產業協會 (SEMI),近來透過技術策略聯盟把電子設計自動化 (EDA) 工具、感測器和軟性電子併入服務平台,以促進物聯網 (IoT)、智慧製造/交通/數據/醫療等五大垂直供應鏈交流及合作,對前述議題亦集結相關廠商在論壇活動做深入探討。
演算法大躍進!終端 AI 推論好整以暇
聯發科技 (MediaTek) 計算與人工智能技術群 (CAI) 處長吳驊表示,現今每年約有 15 億個搭載聯發科晶片的終端問市,以此為根基,他們在 2014 年決定投入邊緣 (Edge) AI 發展,志在重新定義智能裝置。回顧 2016 年以前,雲端在運算力與延遲性略勝一籌,直到 Inception-ResNet 出現,才讓在終端進行推論 (inference) 成為可行,只要 50ms 就可算完一幀 (frame) 圖檔。加之,不少人對雲端仍有隱私與網路環境的顧慮,隨著演算法的複雜度下降、準確度提升,有越來越多推論工作會從雲端移至終端。
聯發科技 (MediaTek) 計算與人工智能技術群 (CAI) 處長吳驊表示,現今每年約有 15 億個搭載聯發科晶片的終端問市,以此為根基,他們在 2014 年決定投入邊緣 (Edge) AI 發展,志在重新定義智能裝置。回顧 2016 年以前,雲端在運算力與延遲性略勝一籌,直到 Inception-ResNet 出現,才讓在終端進行推論 (inference) 成為可行,只要 50ms 就可算完一幀 (frame) 圖檔。加之,不少人對雲端仍有隱私與網路環境的顧慮,隨著演算法的複雜度下降、準確度提升,有越來越多推論工作會從雲端移至終端。

照片人物:聯發科技 (MediaTek) 計算與人工智能技術群 (CAI) 處長吳驊
吳驊指出,2017 年未有專用加速器出現時,深度學習 (Deep Learning) 的運算仍仰賴GPU或CPU之力,無法針對加、乘運算加速,運算力約在 100 GMACs/sec 之譜,頂多只能做影像分類、物件偵測、臉部解鎖或不同場景參數等視覺感知;2018 年,開始有不少晶片廠商將 AI 處理能力加到系統單晶片 (SoC) 中,運算提升至 1TMACs/sec,可做影像分割 (Partition)、深度估算、攝影散景 (Bokeh) 或以個體為基礎等局部物件建構;今後為追求影像品質,將往 10 TMACs/sec 挺進、做夜拍照片強化或像素等級處理,著重超級解析度與降低雜訊。
此外,Google I/O 原本達 100GB 的雲端模型已可縮小至 0.5GB,使演算法與裝置能力皆獲得改善,雙管齊下將能發揮加乘效果、激發更多新應用。例如,化身無人機形式清掃高處灰塵的掃地機器人、或是新興的服務型機器人,會議電話可辨識每個人的聲音、綜整發言內容或翻譯,以及車載相關應用。與此同時,亦為 SoC 帶來考驗:1.深度學習有多層運算,須不停進出記憶體;2.現階段 AI 之不同局部各有其對應的神經網路,須具備多任務 (multi-task) 處理能力;3.被動服務升級為主動服務,長時間開機 (always-on) 引發功耗、散熱和資源配置問題。

圖1:運算力的提升,讓現有裝置的使用者體驗 (UX) 再進階
資料來源:聯發科技提供
抓住邊緣 AI 商機的三大利器
聯發科技內嵌 AI 加速器的單晶片八核心處理器 Helio P90,運算力可達 1.1 TMACs/sec、但功耗僅有 5W,已獲主打拍照、續航力和時尚設計的 Oppo Reno Z 採用。吳驊認為,欲抓住邊緣 AI 商機有三大利器:
1. 特製的硬體和系統設計:須有特殊運算架構支應深度神經網路 (DNN) 的重複操作,以臉部偵測為例,APU 比 CPU 快 20 倍、功耗減少 55 倍,另異質運算系統如何協同作業、極大化效能和能源效率、完整利用運算資源及快速發展 DNN 的靈活度亦是關鍵——DNN 架構可以深、但不宜過胖,以免超出記憶體負荷;
2. 設計自動化:在硬體設計之初就將機器學習 (ML) 納入考量,使其自行搜尋最適合的 DNN 以節省執行時間——將 APU 與 CPU 分別內置在 Helio P90 中對比,APU 執行速度要比 CPU 快 14倍,而經過優化的設計會在精準度與效能之間取得平衡;
3. 整合及靈活的 SoC 平台:為使 AI 演算法在硬體執行更有效率,聯發科技還提供「NeuroPilot 邊緣 AI 平台」——與 AI 處理引擎高度整合、最佳化系統效能、功耗和效率,並兼顧彈性和友善性,冀以 ML 解決更多系統問題,例如,直播時若網路環境不佳會導致畫面出現馬賽克,可利用 AI 對「感興趣區域」(ROI) 加強訓練,改善原本一律以相同位元率 (bitrate) 編碼的缺失,更突顯主角人物。
聯發科技內嵌 AI 加速器的單晶片八核心處理器 Helio P90,運算力可達 1.1 TMACs/sec、但功耗僅有 5W,已獲主打拍照、續航力和時尚設計的 Oppo Reno Z 採用。吳驊認為,欲抓住邊緣 AI 商機有三大利器:
1. 特製的硬體和系統設計:須有特殊運算架構支應深度神經網路 (DNN) 的重複操作,以臉部偵測為例,APU 比 CPU 快 20 倍、功耗減少 55 倍,另異質運算系統如何協同作業、極大化效能和能源效率、完整利用運算資源及快速發展 DNN 的靈活度亦是關鍵——DNN 架構可以深、但不宜過胖,以免超出記憶體負荷;
2. 設計自動化:在硬體設計之初就將機器學習 (ML) 納入考量,使其自行搜尋最適合的 DNN 以節省執行時間——將 APU 與 CPU 分別內置在 Helio P90 中對比,APU 執行速度要比 CPU 快 14倍,而經過優化的設計會在精準度與效能之間取得平衡;
3. 整合及靈活的 SoC 平台:為使 AI 演算法在硬體執行更有效率,聯發科技還提供「NeuroPilot 邊緣 AI 平台」——與 AI 處理引擎高度整合、最佳化系統效能、功耗和效率,並兼顧彈性和友善性,冀以 ML 解決更多系統問題,例如,直播時若網路環境不佳會導致畫面出現馬賽克,可利用 AI 對「感興趣區域」(ROI) 加強訓練,改善原本一律以相同位元率 (bitrate) 編碼的缺失,更突顯主角人物。
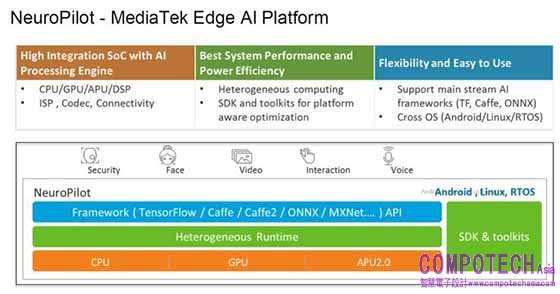
圖2:聯發科技的「NeuroPilot 邊緣 AI 平台」可應用於門禁保全、臉部辨識、人機互動及影音
資料來源:聯發科技提供
資料來源:聯發科技提供
吳驊總結,所有運算單元不外乎是彈性和效率的取捨。聯發科技第一代 AI 晶片著眼於演算法進展快速,因而首重彈性;第二代融合架構針對一定會用到的部分將之固化、增加效率,但仍為處理器保留彈性;第三代進化至多核,供複雜應用所需。接著,是否要將運算和儲存放在一起是下個觀察。深度學習有個好處是:資料可重複使用 (reuse)。若能讓數據在處理器引擎儘量多停留,亦可改善記憶體的使用量。因此,除了延遲性與功耗,消耗多少記憶體資源也是重點指標。
FPGA 強在可客製化、獨立運作且配置靈活
英特爾 (Intel) 可編程解決方案事業部資深嵌入式系統應用工程師周凱楓特別對「加速」敘述:資料通常會經過傳輸、儲存、擷取、整理和分析等階段,2012 年微軟 (Microsoft) 在其資料中心設置了 1,632 個 FPGA 伺服器,預估這個數字未來仍將倍數成長,間接成為 2015 年英特爾出手併購 Altera 的原因之一;2018 年,微軟更進一步將 FPGA 伺服器放到 Azure 雲端。事實上,阿里巴巴、谷歌 (Google)、臉書 (Facebook) 等雲端解決方案提供者 (CSP) 正自發地將 FPGA 部署到雲端,科大訊飛和阿里巴巴更有自行面向語音、影像客製化的 FPGA 卡片。
英特爾 (Intel) 可編程解決方案事業部資深嵌入式系統應用工程師周凱楓特別對「加速」敘述:資料通常會經過傳輸、儲存、擷取、整理和分析等階段,2012 年微軟 (Microsoft) 在其資料中心設置了 1,632 個 FPGA 伺服器,預估這個數字未來仍將倍數成長,間接成為 2015 年英特爾出手併購 Altera 的原因之一;2018 年,微軟更進一步將 FPGA 伺服器放到 Azure 雲端。事實上,阿里巴巴、谷歌 (Google)、臉書 (Facebook) 等雲端解決方案提供者 (CSP) 正自發地將 FPGA 部署到雲端,科大訊飛和阿里巴巴更有自行面向語音、影像客製化的 FPGA 卡片。

照片人物:英特爾 (Intel) 可編程解決方案事業部資深嵌入式系統應用工程師周凱楓
周凱楓指出,傳統資料中心運作是由一台伺服器,經由網路向另一台伺服器完成資料庫詢問,但 FPGA 的強項是:擁有豐富 I/O 且配置靈活,可直接從攝影機或網路抓取資料、中間不須繁重交換動作且能依目的將資料轉送出去;不需 CPU 參與,就能將所有資料庫放到 CDR (Clock and Data-Recovery,時脈資料回復) 做影像預處理或合成,能耗低、效率高;甚至有 AI 晶片商將 FPGA 重新編譯,藉以開發更具成本效益的專用晶片 (eASIC),非常適合利基市場。另一個用例是:若 AI 部分元素的 CPU 運算力不足,亦可將初步結果丟給 FPGA 接手處理。
為使近年併購產生綜效,英特爾還推出 OpenVINO 開源工具套件,讓開發者以「ONE API、ONE Framework」實現多元推論場景——當中多數元件以高階語言建構,不必學習多套編程方法、只需改幾行代碼就能橫跨不同硬體,有兩大組成:Model-Optimizer 編譯工具,可將 TensorFlow 等訓練好的模型轉換成「中介碼」(Intermediate Representation, IR),然後連同篩選準則和推論引擎一起部署到裝置中;Deep Learning Inference Engine 乃基於 C++ 語言的 API,可虛擬硬體並與函式庫整合,將 AI 導入至 CPU、GPU 做推論,但亦有廠商用於訓練 (training)。
周凱楓自評英特爾的 FPGA 優勢:永遠處在最前沿、最利基的地位,尤其利於快速在市場試水溫。有別於同業較聚焦於嵌入式工業應用,英特爾的 FPGA 在雲端勠力更深,且可提供單獨的 FPGA 板卡產品;而 OpenVINO 更是最強裝備,可連結許多週邊資源,抱團打群架。
高效運算,GPU 當仁不讓!
然不可否認,擁有平行運算能力的 GPU 更適合用於「訓練」;不過,輝達 (NVIDIA) 解決方案架構經理康勝閔宣示,GPU 與 CPU、FPGA 或專用晶片並非壁壘分明的競爭、而是協作關係。當 CPU 還依循著摩爾定律 (Moore’s Law) 的軌跡緩步前進時,就在 2013~2019 短短六年間,GPU 的高效運算 (HPC) 已飆速絕塵而去 (從 Fermi 演進到 Volta 不難看出)。NVIDIA GPU 已獲機器學習測試標準 MLPerf 認證為全球運算效能最快者,這不只是硬體軍備競賽,還包括基於前端應用運算特性、自底層作業系統堆疊的演算法、函式庫和軟體開發套件 (SDK)。
然不可否認,擁有平行運算能力的 GPU 更適合用於「訓練」;不過,輝達 (NVIDIA) 解決方案架構經理康勝閔宣示,GPU 與 CPU、FPGA 或專用晶片並非壁壘分明的競爭、而是協作關係。當 CPU 還依循著摩爾定律 (Moore’s Law) 的軌跡緩步前進時,就在 2013~2019 短短六年間,GPU 的高效運算 (HPC) 已飆速絕塵而去 (從 Fermi 演進到 Volta 不難看出)。NVIDIA GPU 已獲機器學習測試標準 MLPerf 認證為全球運算效能最快者,這不只是硬體軍備競賽,還包括基於前端應用運算特性、自底層作業系統堆疊的演算法、函式庫和軟體開發套件 (SDK)。

照片人物:輝達 (NVIDIA) 解決方案架構經理康勝閔
例如,衡量眼前需祭出何種神經網路、並在解析其運算程序後加以優化;該由一台多核心主機處理或多台主機並行。康勝閔還提到,「多處理器」(Multi-processor) 運算為提升效率,晶片商會在既有架構上發展通訊方式;NVIDIA 有鑑於原有 GPU 通道 NVLink,在 GPU 和 GPU 溝通時仍需繞道 CPU 的橋接器、會折損頻寬,故在進入 16 顆 GPU 後改成 NVSwitch,將 GPU 卡片之間的通訊頻寬從300 Gbps 一舉拉升至 2.4 Tbps,大幅加速數據訓練時間。再者,就是設法利用函式庫,以混合精度 (Mixed Precision) 極大化晶片的運算效能。
「異質整合」應對 AI 晶片設計三大挑戰
新思科技 (Synopsys) 策略總監魏志中則強調「異質整合」(Heterogeneous Integration) 的重要。從半導體製程觀點來看,要將數位、類比 IC 和記憶體三種截然不同的製程整合成一個晶片,只得從「系統級封裝」(SiP) 著手;然而,若要兼顧效能、功耗和成本,更值得討論的是:怎麼將不同 CPU 架構集成在一個單晶片中。他預估,邊緣端將囊括 80% 的 AI 市佔,邊緣 AI+IoT 是台灣極好的機會;而每種 AI 應用所需的處理器要求亦不盡相同,AI 邊緣處理器大致可分為 CPU、FPGA 和 ASIC 三類。
新思科技 (Synopsys) 策略總監魏志中則強調「異質整合」(Heterogeneous Integration) 的重要。從半導體製程觀點來看,要將數位、類比 IC 和記憶體三種截然不同的製程整合成一個晶片,只得從「系統級封裝」(SiP) 著手;然而,若要兼顧效能、功耗和成本,更值得討論的是:怎麼將不同 CPU 架構集成在一個單晶片中。他預估,邊緣端將囊括 80% 的 AI 市佔,邊緣 AI+IoT 是台灣極好的機會;而每種 AI 應用所需的處理器要求亦不盡相同,AI 邊緣處理器大致可分為 CPU、FPGA 和 ASIC 三類。

照片人物:新思科技 (Synopsys) 策略總監魏志中
「AI 晶片設計有三大挑戰:處理器架構、記憶體效能與安全機制」,魏志中說。從設計之初的架構探索、演算法優化與記憶體分析,新思皆有完整工具可用:借助 32 位元的純量處理機 (scalar processor)、512 位元的數位訊號處理器 (DSP) 和卷積神經網路 (CNN) 加速器引擎,在晶片效能、功耗與面積取得最佳平衡,並從行為分析協助決策。擴充性 (scalability) 是 AI 晶片設計另一要點。以視訊為例,從過去的 1080P 進化到 4K,運算量成長驚人,晶片須從單核轉變為多核、甚至是多叢集 (multi-cluster) 才夠用,需為日後預留擴充性。
魏志中直言,以往演算法存在「大就是好」的謎思,但現在講究的是怎麼降低模型要求、又能維持一定的精準度。新思科技的直接記憶體存取 (DMA) 引擎,有助於深度學習的層數、頻寬資源與視覺映射器 (visualMap) 的「分割」,增加資料吞吐量。另由於光罩費用高昂,新思驗證平台亦可模擬投片 (tape-out) 後的成果、避免無謂浪費。
「記憶體」與運算單元之互動模式受矚目
在最後的座談環節,眾人對於「記憶體」頗多關注。科技部半導體射月計畫召集人暨中興大學電機系教授張振豪在主持時介紹,這項於去年啟動的四年計畫有六大主軸:感測、記憶體、AI 晶片、IoT 資安、無人載具以及虛擬/擴增實境 (VR/AR),目前有 20 個研發團隊。聯發科技提醒,Computing with Memory 與「記憶體式運算」(In-Memory Computing, IMC) 仍有差異。前者是所有參數旁都要有一個記憶體,就現有架構而言,對效能未必有助益;後者是在記憶體中進行參數與數據乘加,參數就儲存在記憶體中、不用遷移,非發揮性記憶體 (NVM) 尤具意義。
在最後的座談環節,眾人對於「記憶體」頗多關注。科技部半導體射月計畫召集人暨中興大學電機系教授張振豪在主持時介紹,這項於去年啟動的四年計畫有六大主軸:感測、記憶體、AI 晶片、IoT 資安、無人載具以及虛擬/擴增實境 (VR/AR),目前有 20 個研發團隊。聯發科技提醒,Computing with Memory 與「記憶體式運算」(In-Memory Computing, IMC) 仍有差異。前者是所有參數旁都要有一個記憶體,就現有架構而言,對效能未必有助益;後者是在記憶體中進行參數與數據乘加,參數就儲存在記憶體中、不用遷移,非發揮性記憶體 (NVM) 尤具意義。
英特爾以「將大象放進冰箱」比喻要將不停膨脹的資料硬塞進有限記憶體的困境,主張應從終端演算法、中介軟體編譯到底層硬體,以「時間軸」為依據而努力,並透露英特爾正在研發 IMC 的新產品,惟軟體層創新仍是重中之重。新思科技表示記憶體頻寬可從兩方面思考:伺服器頻寬可提升至 Gigabit 等級,惟與處理器的路由途徑關係極大,而熱耗可藉由新興製程搞定;晶片互連頻寬則依恃分割、DMA 技術,外部可透過 3D IC 封裝整合。






