
NVIDIA 研究團隊在美國西雅圖舉行的國際電腦視覺與圖型識別會議上 展示視覺生成式 AI 的進步
前言:
NVIDIA Research 將發表 50 多篇論文,介紹AI軟體在創意產業、自動駕駛載具開發、醫療保健和機器人領域的潛在應用

NVIDIA 研究人員處於快速發展的視覺生成式人工智慧(AI)領域的尖端,開發新技術來創建和解釋圖像、影片和 3D 環境。
其中 50 多個項目將在 6 月 17 日至 21 日在西雅圖舉行的國際電腦視覺與圖型識別會議(CVPR)上展示。其中兩篇論文入圍 CVPR 最佳論文獎:一篇關於擴散模型的訓練動力學,另一篇關於自動駕駛汽車的高解析度地圖——。
NVIDIA 也是 CVPR 自動駕駛大挑戰賽(Autonomous Grand Challenge)中大規模端到端駕駛的獲勝者,這是一個重要的里程碑,展示了公司將生成式 AI 用於全面的自動駕駛模型。這項勝出的作品在全球超過 450 份參賽作品中脫穎而出,並獲得了 CVPR 的創新獎。
NVIDIA 在CVPR 的研究包括可輕鬆客製以描繪特定物件或角色的文字到圖像模型、用於物件姿勢估計的新模型、編輯神經輻射場(NeRFs)的技術以及可以理解迷因的視覺語言模型。其他論文介紹了汽車、醫療保健和機器人等產業的特定領域創新。
總體而言,這項工作引入了強大的AI模型,可以使創作者更快地實現他們的藝術視覺,加速用於製造的自主機器人的訓練,並透過幫助處理放射學報告來支援醫療保健專業人員。
NVIDIA 學習和感知研究副總裁 Jan Kautz 表示:「人工智慧,尤其是生成式AI,代表了一項關鍵的科技進步。在 CVPR 上,NVIDIA研究正在分享我們如何突破任何可能的界限:從可以為專業創作者提供強大支持的強大圖像生成模型,到可以幫助實現下一代自動駕駛汽車的自動駕駛軟體。」
在 CVPR 上,NVIDIA 也發布了 NVIDIA Omniverse Cloud Sensor RTX,這是一組微服務,可實現物理上精確的感測器模擬,從而加速各種全自動機器的開發。
不需再微調:JeDi 簡化客製化影像生成
擴散模型是基於文字提示生成圖像的最受歡迎方法,而使用擴散模型的創作者通常心中會有特定的角色或物件。 例如,他們可能正在規劃一隻動畫老鼠主題的故事分鏡或為特定玩具構思的廣告活動。
先前的研究使這些創建者能夠透過微調來個性化擴散模型的輸出,讓使用者在客製化資料集上訓練模型以專注於特定主題,但這個過程可能非常耗時,並且對於普通使用者來說難以使用。
JeDi 是約翰霍普金斯大學、芝加哥豐田理工學院和 NVIDIA 的研究人員發表的一篇論文,其中提出了一種新技術,允許用戶使用參考圖像在幾秒鐘內輕鬆個性化擴散模型的輸出。團隊發現該模型達到了最先進的品質,顯著優於現有的基於微調和免微調的方法。
JeDi 還可以與檢索增強生成(RAG)結合,產生特定於資料庫的視覺效果,例如品牌的產品目錄。

新的基礎模型完善了姿勢
NVIDIA 研究人員在CVPR 也展示了FoundationPose,這是一種用於物體姿態估計和追蹤的基礎模型,可以在推論過程中立即應用於新物體,而無需進行微調。
該模型在普遍使用的物體姿態估計基準測試中創下了新紀錄,它使用一小組參考圖像或物體的 3D 表示來理解其形狀。然後,它可以識別並追蹤該物件如何在影片中以 3D 方式移動和旋轉,即使在照明條件不佳或有視覺障礙的複雜場景中也是如此。
FoundationPose 可用於工業應用,幫助自主機器人識別和追蹤與其互動的物體。它還可以用於擴增實境應用程式,其中AI模型用於在即時場景上疊加視覺效果。
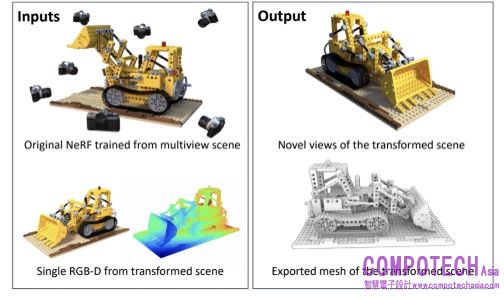
NeRFDeformer 使用單一快照轉換 3D 場景
NeRF 是一種 AI 模型,可根據從環境中不同位置拍攝的一系列 2D 影像來渲染 3D 場景。在機器人等領域,NeRF 可用於產生複雜現實場景的沉浸式 3D 渲染,例如雜亂的房間或建築工地。然而,要進行任何更改,開發人員需要手動定義場景的轉換方式,或完全重新製作 NeRF。
伊利諾大學香檳分校和 NVIDIA 的研究人員利用 NeRFDeformer 簡化了這個過程。該方法在 CVPR 上提出,可以使用單一 RGB-D 影像成功地轉換現有的 NeRF,該影像是普通照片和深度圖的組合。深度圖會捕捉場景中每個物件與相機的距離。
VILA視覺語言模型掌握畫面
NVIDIA與麻省理工學院在CVPR的研究合作推進了視覺語言模型的技術,這些是能處理影片、圖像和文字的生成式AI模型。
該團隊開發了VILA,這是一系列表現優於先前神經網絡的開源視覺語言模型,能夠在測試AI模型如何回答關於圖像的問題的主要基準測試上表現出色。VILA獨特的預訓練過程解鎖了新的模型能力,包括強化的世界知識、更強的上下文學習能力和跨多個圖像進行推理的能力。

圖說:VILA能透過多張圖片或影格了解迷因和推理
VILA 模型系列可使用 NVIDIA TensorRT-LLM開源函式庫進行推論最佳化,並且可以部署在資料中心、工作站甚至邊緣設備的 NVIDIA GPU 上。
在 NVIDIA 技術部落格 和GitHub 上了解有關 VILA 的更多資訊。
生成式AI推動自動駕駛、智慧城市研究
在CVPR ,NVIDIA 撰寫的論文中有十幾篇專注於自動駕駛汽車研究。與自動駕駛相關的亮點包括:
NVIDIA贏得CVPR自動駕駛大挑戰的應用研究成果,請參考影片。
NVIDIA AI研究副總裁Sanja Fidler將於6月17日在自動駕駛研討會上介紹視覺語言模型。
由多倫多大學和NVIDIA研究人員合著的《Producing and Leveraging Online Map Uncertainty in Trajectory Prediction》一文,入選CVPR最佳論文獎的24個決賽入圍作品之一。
同樣在 CVPR 上,NVIDIA 為 AI 城市挑戰賽貢獻了有史以來最大的室內合成資料集,幫助研究人員和開發人員推進智慧城市和工業自動化解決方案的開發。該挑戰賽的資料集是使用 NVIDIA Omniverse產生的,這是一個 API、SDK 和服務平台,使開發人員能夠建立基於通用場景描述(OpenUSD)的應用程式和工作流程。
NVIDIA Reasearch在全球擁有數百名科學家和工程師,團隊專注於AI、電腦圖形、電腦視覺、自動駕駛汽車和機器人等主題。了解更多有關 NVIDIA Research在CVPR的更多資訊。






