

工研院產業科技國際策略發展所系統IC與製程研究部范哲豪
以往AI產品都是應用在手機,PC比較大型或價格比較貴高端裝置,但隨著裝置趨向智慧化也逐漸導入AI功能。市面上很多電子產品都是運用MCU(微控制器) 設計, MCU已經自然的融入在我們生活當中。現今,隨著智慧化趨勢,眾多企業開始在MCU上運用AI的特點,注重MCU結合AI 的開發。
工研院系統IC與製程研究部范哲豪表示, 在MCU上面運用AI的機會非常多,生活中應用MCU的行業非常廣泛。應用的好處在於降低功耗、降低成本、快速上市、直接在前端處理不需要再丟到雲端運算;相對的,也有三個難度,第一個是算力非常弱,從運算時脈傳統的8 bit,到ARM的cortex M3系列最多做到120 MHz,跟傳統Embedded或CPU GHz相比有著明顯的差距。第二則是缺少建模和訓練工具,要在MCU上實現AI計算的整體流程必須分為PC端工具以及MCU終置端,在PC端收集數據集,使用AI建模軟體來訓練模型,在MCU硬件與數據部份是運行AI模型的基礎環境,通常只做推論而不做學習。而最後一點則是缺少集成工具,對於MCU來說,以往都在雲端運算並建模,但建完後的模都是非常大的,不適合MCU去使用,還有開發工具難度,這都是目前廠商比較缺乏。
而在機會上,可以看到MCU廠商都在增加效能,像是ARM的cortex M7系列已經可以跑到1 GHz,可以處理一些外部的DRAM。MCU的運算時脈越來越快,硬體雖然可以跑AI的運算,但要在演算法上更加精進,須要有另外AI加速器廠商的搭配,讓開發工具做改善。
tinyML被受重視
在大趨勢朝向更精簡的模型下, TinyML受到重視。 tinyML是指超低功耗的機器學習在物聯網各種裝置端微控制器的運用,而tinyML通常功耗為毫瓦(mW)級別甚至更低,因此可以支援各種不同的電池驅動設備,和需要始終在線的應用,例如智能攝像頭、遠端遙控、可穿戴裝置等等設備。無論是算法、網路、低於100KB的ML模型,tinyML都已取得重大突破。今年2月在美國矽谷舉行的產業會議,tinyML議題更加被重視,且多家廠商如英偉達、ARM、高通、GOOGLE、微軟、三星以及各家新創公司都紛紛展示最新成果。
在大趨勢朝向更精簡的模型下, TinyML受到重視。 tinyML是指超低功耗的機器學習在物聯網各種裝置端微控制器的運用,而tinyML通常功耗為毫瓦(mW)級別甚至更低,因此可以支援各種不同的電池驅動設備,和需要始終在線的應用,例如智能攝像頭、遠端遙控、可穿戴裝置等等設備。無論是算法、網路、低於100KB的ML模型,tinyML都已取得重大突破。今年2月在美國矽谷舉行的產業會議,tinyML議題更加被重視,且多家廠商如英偉達、ARM、高通、GOOGLE、微軟、三星以及各家新創公司都紛紛展示最新成果。
傳統MCU廠商在MCU+AI的布局
瑞薩e-AI端點嵌入式設備人工智慧應用
瑞薩電子(Renesas)從端點智慧入手,而不只靠在雲端使用大資料來解決。憑藉靈活可擴展的嵌入式人工智慧(e-AI)概念,瑞薩電子面向未來提供即時低功耗人工智慧處理解決方案,以滿足端點嵌入式設備人工智慧應用的特定需求。
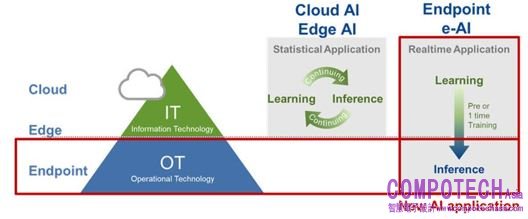
圖:e-AI概念
瑞薩的可動態重配置處理器(DRP)的AI加速器,可以搭配瑞薩自身的MCU做應用。瑞薩提出e-AI(嵌入式人工智慧)開發環境,可在MCU實現AI推論,可以把模型在e2 studio的工具裡面轉換成想要的形式,並且符合C/C++。
NXP的eIQ工具計畫
NXP的el機器學習軟體開發環境支持在NXP MCU、iMX RT跨界處理器(該詞由NXP創造,形容新裝置類型,兼具應用處理器的性能及MCU的易用性、低功耗與即時操作)和iMX系列和SoC上使用機器學習算法。eIQ軟體包括推理引擎、神經網路編譯和優化庫 。這工具可以支援NXP MCU、i.MX RT跨界處理器以及i.MX系列SoC上機器學習算法。
NXP的el機器學習軟體開發環境支持在NXP MCU、iMX RT跨界處理器(該詞由NXP創造,形容新裝置類型,兼具應用處理器的性能及MCU的易用性、低功耗與即時操作)和iMX系列和SoC上使用機器學習算法。eIQ軟體包括推理引擎、神經網路編譯和優化庫 。這工具可以支援NXP MCU、i.MX RT跨界處理器以及i.MX系列SoC上機器學習算法。
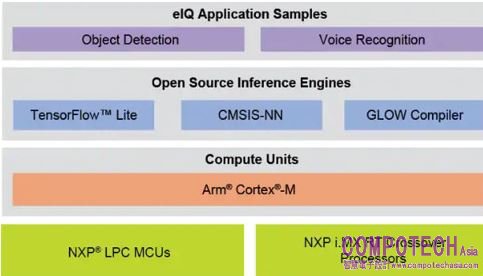
圖:eIQ應用案例
eIQ框架包含Cortex-M、A核以及DSP、GPU和ML加速器,其中ML加速器可以跨平台、跨處理器和MCU。
Microchip memBrain™神經形態記憶體解決方案,協助AI應用程式系統架構規劃
Microchip透過旗下子公司冠捷半導體(SST),推出可大幅降低功耗的類比記憶體技術 — memBrain™神經形態記憶體解決方案。由於當前的神經網路模型可能需要50M或更多的突觸來處理,因此為晶片外DRAM提供足夠的頻寬變得困難,成為神經網路計算的瓶頸,同時導致整體計算功耗的提高。
Microchip透過旗下子公司冠捷半導體(SST),推出可大幅降低功耗的類比記憶體技術 — memBrain™神經形態記憶體解決方案。由於當前的神經網路模型可能需要50M或更多的突觸來處理,因此為晶片外DRAM提供足夠的頻寬變得困難,成為神經網路計算的瓶頸,同時導致整體計算功耗的提高。
Microchip針對神經網路的向量矩陣乘法(VMM)執行進行優化,透過類比儲存計算方法改進VMM的系統架構規劃,提高邊緣AI推理能力。與傳統的數位DSP和SRAM/DRAM的方法相比,新產品的功耗降低了10到20倍。
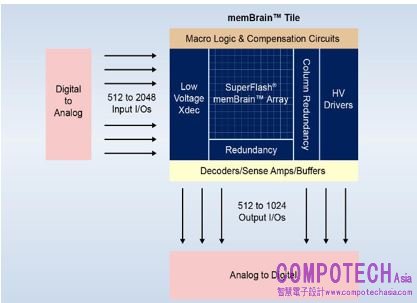
圖:memBrain™神經形態記憶體解決方案
Syntiant就是採用memBrain在即將推出的類比神經網路處理器實現可提供超低功耗的儲存計算。
意法半導體推動Edge AI運作在嵌入式節點設備的技術
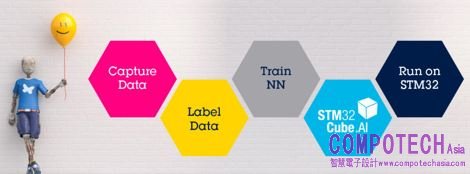
圖:STM32人工神經網路解決方案
意法半導體(ST)也為開發工具做出創新。ST Cube.AI人工智慧神經網路開發套件,目標是將AI導入採用MCU的智慧設備,位於節點邊緣,以及物聯網,智慧建築、工業和醫療應用中的嵌入式設備。
現在開發人員可以使用STM32Cube.AI將預先訓練的神經網路轉換成可在STM32 微控制器上運作的C程式碼,以及經過優化的函數庫。
STM32Cube.AI附帶即用型軟體功能包,其中包括用於識別人類活動和音頻情境分類的範例代碼,可在ST SensorTile 參考板和ST BLE Sensor行動App立即使用這些範例程式碼。
使用者可以在意法半導體的STM32CubeMX MCU軟體程式碼產生器的生態系統內配置和下載STM32Cube.AI擴充包。
今天,該工具支援Caffe、Keras(具備TensorFlow後台)、Lasagne、ConvnetJS框架和Keil、IAR、System Workbench等IDE開發環境。
Arm供數十多億個裝置應用的終端人工智能
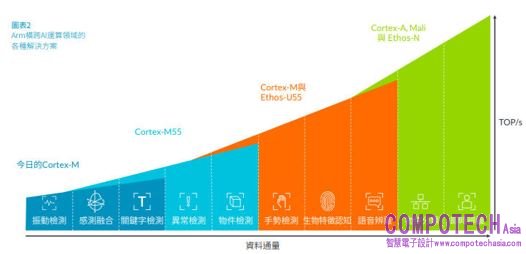
Arm橫跨AI運算領域的解決方案
Arm Cortex-M55處理器與Ethos-U55微型神經網路處理器將終端人工智能的好處推向數十多億個裝置與人們。它們為微控制器提供顯著的AI效能提升,帶動了次世代的物聯網與嵌入式裝置。它們延伸了業界最廣的ML處理解決方案的產品選項,並維持統一的軟體工具,同時大幅簡化開發人員的工作,為運算帶來全新的世代。
Arm Cortex-M55是第一個使用Arm Helium向量處理技術的處理器。與前一代的Cortex-M處理器相比,它的ML效能最多可以提升15倍,DSP效能提升五倍。針對各式各樣的物聯網使用案例。對於由電池驅動的物聯網裝置,這顆處理器整合了不同的AI技術,同時兼顧系統成本與耗電量方面的限制。
Arm Ethos-U55是業界第一個為微控制器級裝置設計的微神經網路處理器。該裝置整合在數百萬開發人員熟悉的單一Cortex-M工具鍊裡。也因此,它提供傑出的效能提升,但卻不會增加軟體的複雜性。當Ethos-U55與 Cortex-M55結合後,與基於Cortex-M設計的現有系統相比,ML工作負載效能最高可以提升480倍,而16奈米製程讓它外型最小可縮至0.1平方毫米,可供成本敏感與有低耗電需求的AI應用使用。
新創公司在MCU+AI的產品布局
Syntiant與Sensory合作AI音訊辨識處理
2020年CES展會上,Syntiant與Sensory宣布,Sensory高性能TrulyHandsFree喚醒詞引擎與語音控制解決方案,支援Syntiant的微瓦級(microwatt-power)神經決策處理器(NDP,Neural Decision Processors)。
Syntiant的NDP 100 與NDP 101該系列晶片可以辨識多達63個英文字母或其他感測器模式,同時消耗功耗僅150mW,能耗表現比典型的微控制器提高了200倍。將用於關鍵字辨識(Keyword spotting)、喚醒詞檢測(wake word detection)、喇叭辨識、語音事件辨別和感測器分析處理。
NDP 100可以置入空間受限的手機和助聽器中。NDP 101則可做為智慧喇叭等大型系統中的主要系統單晶片。兩款產品皆搭載具112-KB RAM記憶體的Arm Cortex-M0 核心。
XMOS的Xcore.AI「跨界處理器」
英國語音與音訊方案供應商XMOS發表專用於機器學習的Xcore處理器核心,從而為人工智慧物聯網(AIoT)應用打造新的跨界處理器(crossover processor)。機器學習版Xcore.ai處理器量產成本可望低於1美元。
英國語音與音訊方案供應商XMOS發表專用於機器學習的Xcore處理器核心,從而為人工智慧物聯網(AIoT)應用打造新的跨界處理器(crossover processor)。機器學習版Xcore.ai處理器量產成本可望低於1美元。
Xcore.ai採用XMOS專有的Xcore架構。Xcore本身建立在稱為邏輯核心的建構模組上,可用於I/O、DSP、控制功能或AI加速。在每個圖塊(tile)中有8個邏輯核心,每個Xcore.ai晶片中有2個tile,設計人員可以選擇為每項功能分配多少核心。每個tile中還包含記憶體、算數邏輯單元(ALU)以及與邏輯核心共享存取權限的向量單元。
Eta Compute的ECM3532
AI晶片初創公司Eta Compute推出首款量產的邊緣AI晶片ECM3532,以僅100 µW 的功率可實現物聯網中的在線圖像處理和傳感器應用,號稱能效是其競品的100-1000倍。ECM3532為雙核(Arm Cortex-M3和NXP CoolFlux DSP)SoC,可支持用於電池供電或能源採集設計的微瓦級傳感氣融合運用。
Eta Compute和Edge Impulse宣布合作,雙方將攜手合作,使用ECM3532和線上TinyML平臺Edge Impulse,來促進機器學習的開發和部屬。
Gree Waves的GAP8多核心處理器
法國無晶圓廠IC設計公司GreeWaves Technologies 即將投片其GAP8多核心處理器,GAP8處理器來自義大利波隆納大學與瑞士蘇黎世聯邦理工學院開發的RISC-V開放源碼軟體PULP核心技術轉移。GAP8採用8顆PULP核心以及1個TensorFlow處理器元(TPU),為基於硬體的模式匹配應用加速卷積神經網路。
GAP8處理器能夠捕捉、分析、分類並處理大量融合數據源,如圖像、聲音或振動。處理器經過優化後可以執行圖像和音頻算法,包括卷積神經網路(CNN)推斷。這款晶片的設計目的在於導入位於AI、IoT和微控制器可能都使用到的電池終端設備。
Esperanto 64位元7nm處理器
Esperanto即將推出的64位元7nm處理器,Esperanto表示它將利用OCP(Open Compute Platform,開放計算平台)、Facebook的Pytorch框架、Glow編譯器以及ONNX(Open Neural Network Exchange,開放神經網路交換)等標準來加速人工智慧和機器學習工作流。
Esperanto即將推出的64位元7nm處理器,Esperanto表示它將利用OCP(Open Compute Platform,開放計算平台)、Facebook的Pytorch框架、Glow編譯器以及ONNX(Open Neural Network Exchange,開放神經網路交換)等標準來加速人工智慧和機器學習工作流。
上數晶片的設計是可以獲得許可的,它在單個晶片上封裝了超過1000個ET-Minion RISC-V晶片。根據該公司的說法,晶片設計用於提供每瓦效率最佳的TeraFlops性能,在單個晶片上用分布式內存架構提高處理器的處理利用率並消除內存帶寬瓶頸。
Picovoice的軟體語音AI
「Picovoice」它生產的軟體可以辨識語音命令,它只是運行在一個價格不超過幾美元的小微處理器上嗎?目前已經在與各大家電公司合作開發語音控制設備
「Picovoice」它生產的軟體可以辨識語音命令,它只是運行在一個價格不超過幾美元的小微處理器上嗎?目前已經在與各大家電公司合作開發語音控制設備
傳統的神經網路多使用長數位數的數字進行計算,而Picovoice使用的是非常短的數字,甚至二進制的1和0,這就使得AI可以在速度慢得多的晶片上運行。這種折衷方案塑造出來的,並不是一個很強的機器人;一個咖啡機的語音辨識人公智慧只需要辨識大約200個單字。
被蘋果收購的Xnor.ai
蘋果以2億美元收購一家開發以裝置運行人公智慧的新創公司Xnor.ai
Xnor.ai的技術標榜能讓低階硬體執行AI演算法,預計能強化iphone相機的影像處理能力,減少耗電力,甚至能用於智慧音響HomePod,以AI提供智慧家庭功能。
蘋果以2億美元收購一家開發以裝置運行人公智慧的新創公司Xnor.ai
Xnor.ai的技術標榜能讓低階硬體執行AI演算法,預計能強化iphone相機的影像處理能力,減少耗電力,甚至能用於智慧音響HomePod,以AI提供智慧家庭功能。
包括英特爾的視覺分析應用開發工具包OpenVINO以及以20美元打響名號的AI連往攝影機Wyze Cam,都採用了Xnor.ai的AI技術。
無人機的應用
來自蘇黎世聯邦理工及義大利博洛尼大學的工程師表示,他們已經製造出世界上最小的自主式無人機。
在超小型四翼無人機Crazyflie 2.0上裝配了一款超低功耗攝像頭和GAP8微處理器,並植入了定制的神經網路演算法。這些擴展,只為無人機增加了5g的重量,以及1%的額外功耗(94毫瓦)。
來自蘇黎世聯邦理工及義大利博洛尼大學的工程師表示,他們已經製造出世界上最小的自主式無人機。
在超小型四翼無人機Crazyflie 2.0上裝配了一款超低功耗攝像頭和GAP8微處理器,並植入了定制的神經網路演算法。這些擴展,只為無人機增加了5g的重量,以及1%的額外功耗(94毫瓦)。
GAP8的主要任務是接收圖像,並運行其AI演算法DroNet,一個羽量級殘差卷積神經網路(CNN)架構。通過該演算法預測轉向角度和碰撞概率,以實現四旋翼飛行器在各種室內和室外環境中的安全自主飛行。
裝置端MCU+AI晶片是未來的發展趨勢
范哲豪表示,裝置端MCU+AI晶片因具低延遲、高隱私等特性是未來的發展趨勢。而新舊MCU廠商的策略大不同,傳統廠商會以ARM的方式為主,新創則不一定。但針對軟體的部分, MCU廠商除了專注在精進開發工具上面,搭配一些軟體的廠商,便可以從軟硬體、開發工具上面來做一個有效的結合,對未來加入市場會是一個很好的幫助。
范哲豪表示,裝置端MCU+AI晶片因具低延遲、高隱私等特性是未來的發展趨勢。而新舊MCU廠商的策略大不同,傳統廠商會以ARM的方式為主,新創則不一定。但針對軟體的部分, MCU廠商除了專注在精進開發工具上面,搭配一些軟體的廠商,便可以從軟硬體、開發工具上面來做一個有效的結合,對未來加入市場會是一個很好的幫助。





