
TOP500 榜單上的超級電腦採用 NVIDIA 技術,以達到加速節能的目標
前言:
全球速度最快的十套超級電腦中,有八套採用 NVIDIA 的技術來加快運算速度NVIDIA Selene 這套運算速度最快的工業超級電腦在美國亮相,其擁有領先業界的節能省電表現

最新的TOP500 超級電腦排行榜描繪出現代科學運算領域的發展前景,利用人工智慧 (AI) 與資料分析技術來擴大這個領域,並透過 NVIDIA 的技術來加快其運算速度。
目前全球運算速度前十名的超級電腦中,有八套包括分布在美國、歐洲及中國最強大的超級電腦系統,都採用了 NVIDIA GPU 或 InfiniBand 網路技術,或是兩者兼備。
在最新的 TOP500 超級電腦排行榜中,有三分之二 (333套) 的超級電腦均採用 NVIDIA 的技術(現已完全收購 Mellanox);而在 2017 年 6 月的排行榜上,合計只有 203 套的超級電腦採用當時還是獨立兩間公司的技術,只佔總數不到一半的數量,相較起來目前的數量可謂大幅增加。
榜單中有近四分之三 (73%) 的全新 InfiniBand 系統採用了 NVIDIA Mellanox HDR 200G InfiniBand,展現出迅速採用最新智慧互連資料傳輸速度的接受度。
自 2019 年 11 月的榜單以來,使用 HDR InfiniBand 的 TOP500 超級電腦數量幾乎增加了一倍。總體而言,榜上有 141 套超級電腦採用 InfiniBand 的技術,自 2019年 6 月以來成長了 12%。
圖一_越來越多的 TOP500 超級電腦採用了 NVIDIA 的GPU、Mellanox 網路技術,或是兩者兼備
NVIDIA Mellanox InfiniBand 與乙太網網路連接了 TOP500 超級電腦中的305套系統 (61%),其中包含 141 套使用 InfiniBand 的系統與 164 套使用乙太網路的系統 (63%)。
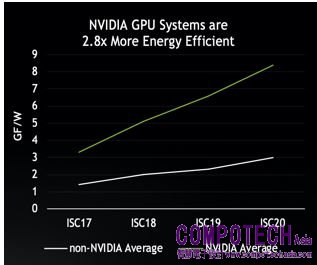
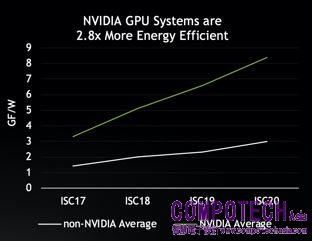
在能源使用效率方面,使用 NVIDIA GPU 的系統從眾多系統中脫穎而出,能源使用效率平均較未使用 NVIDIA GPU 的系統提升 2.8 倍 (測量單位為每秒十億次浮點運算/ 瓦)。
由此可知在 TOP500 排行榜前25名的超級電腦中,有二十套系統採用 NVIDIA GPU 的原因。
圖二_ NVIDIA GPU 協助 TOP500 排行榜上的超級電腦達到節能省電的目標
這種節能效率最好的例子就是 NVIDIA 內部研究叢集的最新生力軍 Selene (上圖)。該系統在最新的 Green500 排行榜中奪得亞軍,並且在 Linpack 基準測試中以 27.5 petaflops 的成績,位列整體 TOP500 排行榜的第七名。
每瓦20.5 gigaflops 的表現讓 Selene 與 Green500 榜單上榜首的表現相差無幾,而 Green500 榜單的榜首為一套效能排名為第 394 名、體積較小的系統奪得。
在前100名的系統中,Selene 是唯一一套突破每瓦 20 gigaflops 門檻的系統,同時也是全球最強大工業超級電腦名單上的第二名,僅次於義大利能源巨頭 Eni S.p.A. 集團奪下第六名的工業系統,該系統同樣採用 NVIDIA 的 GPU。
在節能省電效率方面,Selene 較未使用 NVIDIA GPU 的 TOP500 系統平均高出 6.8倍。Selene 優秀的運算及能源效率使用表現,要歸功於 NVIDIA A100 GPU 的第三代 Tensor Core,既加快了傳統模擬作業的 64 位元數學運算速度,也加快了低精度的 AI 運算工作。
NVIDIA 只用了不到四週的時間便打造出 Selene 系統,能有如此亮眼的表現讓人刮目相看。而當時工程師使用了 NVIDIA 的模組化參考架構,才能夠快速組裝出 Selene 系統。
NVIDIA 的模組化參考架構指南定義了 NVIDIA 所謂的 DGX SuperPOD。它是以用於打造現代資料中心強大又靈活的構件,也就是 NVIDIA DGX A100 系統為基礎。
彈性十足的 DGX A100 系統現已上市,在一具 6U 伺服器中搭載了八個 A100 GPU,並且採用 NVIDIA Mellanox HDR InfiniBand 網路技術。它是為了加快高效能運算、資料分析,以及包括訓練和推論在內的 AI 運算作業,以及快速部署等目的而誕生的產品。
從系統擴大到 SuperPOD
任何組織使用這項參考設計,都能快速建立一個世界級的運算叢集。它展示了如何利用高效能的 NVIDIA Mellanox InfiniBand Switch,以搭建樂高積木的方式來連接二十套 DGX A100 系統。
任何組織使用這項參考設計,都能快速建立一個世界級的運算叢集。它展示了如何利用高效能的 NVIDIA Mellanox InfiniBand Switch,以搭建樂高積木的方式來連接二十套 DGX A100 系統。
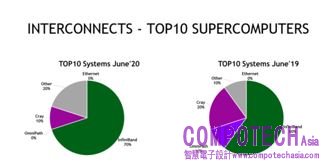
圖三_前十名的超級電腦中,現在有七套採用 InfiniBand 網路技術來加快運算速度,包括分布在中國、歐洲與美國最強大的超級電腦系統
四名操作員可以在短短一小時內架設一個搭載二十套系統的 DGX A100 運算叢集,進而建立一個運算速度達到 2-petaflops 並進入 TOP500 榜單的系統。這樣的系統設計能夠在標準資料中心的電源和散熱能力範圍內穩定運行。
工程師透過額外加入一層 NVIDIA Mellanox InfiniBand Switch,便能將這二十套系統單元中的十四套串連起來,打造出 Selene 系統,其中包含:
● 280 套 DGX A100 系統
● 2,240 個 NVIDIA A100 GPU
● 494 個 NVIDIA Mellanox Quantum 200G InfiniBand Switch
● 56 TB/s 網路結構
● 7PB 高效能全快閃儲存裝置
● 280 套 DGX A100 系統
● 2,240 個 NVIDIA A100 GPU
● 494 個 NVIDIA Mellanox Quantum 200G InfiniBand Switch
● 56 TB/s 網路結構
● 7PB 高效能全快閃儲存裝置
Selene 系統最重要的規格之一,便是提供超過 1 exaflops 的 AI 運算效能。此外,Selene 系統僅使用了系統中的十六套 DGX A100 系統,在 TPCx-BB 這項重要的資料分析基準刷下全新紀錄,其效能表現較任何其它系統高出二十倍。
當 AI 與分析成為科學運算領域中一部分新的要求條件時,這項結果便顯得極為重要。
各地的研究人員紛紛使用深度學習和資料分析技術,以預測最有可能得到實驗成果的領域,這項方法將能減少研究人員寶貴的時間與金錢來進行實驗,並加快取得科學研究成果的速度。
舉例來說,目前正在使用 NVIDIA 上個月甫推出的 A100 GPU,打造六套尚未進入 TOP500 排行榜的系統。這六套系統將加快高效能運算與 AI 的融合,以定義科學的新時代。
TOP500 榜單擴大了科學運算領域的發展
其中一套便是阿貢國家實驗室 (Argonne National Laboratory) 所使用的超級電腦系統,研究人員將使用由 24 套 NVIDIA DGX A100 系統組成的運算叢集來掃描數十億種藥物,以尋找治療新冠肺炎的方法。
其中一套便是阿貢國家實驗室 (Argonne National Laboratory) 所使用的超級電腦系統,研究人員將使用由 24 套 NVIDIA DGX A100 系統組成的運算叢集來掃描數十億種藥物,以尋找治療新冠肺炎的方法。
阿貢國家實驗室運算生物學家 Arvind Ramanathan 在一份 A100 GPU 首批用戶的心得報告中表示:「許多工作難以在電腦上進行模擬,因此我們透過 AI 指導下一步的採樣地點和時間。」
美國國家能源研究科學計算中心 (NERSC) 也為在自家超級電腦系統 Perlmutter 上運行的多個研究項目引進了 AI 技術,這套準 exascale 級的超級電腦搭載了 6,200 個 A100 GPU。
舉例來說,其中一個研究案將使用強化學習來控制光源實驗,另一個研究案將把生成模型用在高能物理探測器上,重現昂貴的模擬過程。
德國慕尼黑的研究人員使用 Summit 超級電腦上的 6,000 個 GPU 來訓練自然語言模型,以加快分析新冠病毒的蛋白質。如此可見這些頂尖的 TOP500 系統正在超越過去使用雙精度數學進行的模擬作業。

圖四_人工智慧、資料分析與邊緣串流重新定義了科學運算領域
科學家們開始走進深度學習與分析領域,也利用雲端運算服務,甚至以串流方式,從網路邊緣的遠端儀器取得資料。這些元素共同構成了由 NVIDIA 加速的現代科學運算領域的四大支柱:
模擬:橡樹嶺國家實驗室的研究人員在對抗新冠病毒的過程中,透過在 Summit 超級電腦的 GPU 上運行 AutoDock,於 24 小時內模擬了超過二十億種化合物。
模擬:橡樹嶺國家實驗室的研究人員在對抗新冠病毒的過程中,透過在 Summit 超級電腦的 GPU 上運行 AutoDock,於 24 小時內模擬了超過二十億種化合物。
● 人工智慧與資料分析:Spark 3.0 的 GPU 加速技術現已加快了機器學習管道關鍵又耗時的前端處理作業。
● 科學邊緣串流:歐洲核子研究機構 (CERN) 近日宣佈 NVIDIA GPU 將使其大型強子對撞機內粒子對撞事件產生的海量資料減少 500 倍。
● 視覺化:NVIDIA 的 IndeX 與 Magnum IO 軟體用於製作登陸火星的視覺化內容,這是全球規模最龐大的互動式即時立體資料視覺化項目。
這只是一個大趨勢的一部分,研究人員與企業都在尋找從雲端到網路邊緣,能夠加快處理 AI 和分析作業的技術。這正是全球最大的雲端服務供應商及頂尖 OEM 業者均採用 NVIDIA GPU 的原因。
最新的 TOP500 榜單中反映出 NVIDIA 在 AI 與高效能運算普及化方面的努力。任何想要打造頂尖運算力的公司,都可以使用 NVIDIA 的技術,像是用於支援全球最強大系統的 DGX 系統。
最後 NVIDIA 祝賀在日本 Fugaku 超級電腦背後開發的工程師奪得 TOP500 排行榜的冠軍,同時這也表示 Arm 架構正在逐步落實成為高效能運算領域具可行性的選擇之一。這也是 NVIDIA 一年前宣布將在 Arm 處理器架構上,提供旗下 CUDA 加速運算軟體的原因之一。






