
RISC(精簡指令集)的設計理念長久性地改變了運算的面貌,在本文中,我們所將介紹的是一項全新關於神經網路加速器功能的方案。
從RISC的演變情況來看,重點在於小型、高靈活度和低層級的指令集,其允許更深入的管線流通、將複雜性轉移至編譯器以及提供更高的整體性能,RISC幾十年來一直主導著電腦架構,並且是現今領先處理器架構的基礎。
然而RISC的優勢在於某些操作侷限於少量特定操作的應用,該運算問題的典型實例,是卷積神經網路(CNN)推理,其中絕大多數的運算和頻寬要求是針對少量層,例如卷積、池化和活化;在此設定中,需要使用硬體加速器並進行修復功能,以達成這些常見的任務,執行這些操作之外的任何動作,都將導致硬體無法打造最佳狀態,必須消耗更多的功耗和面積,以達到每秒相同的目標操作數。
ROSC概念
圍繞高度最佳化的固定功能硬體構建神經網路加速器(NNA)可適切地滿足多數網路運算需求,但難免會留下大量相對不常見的層型,這些通常只佔運算需求的一小部分,並且可能包括諸如softmax、argmax 和globalreduces等,因此我們需要一個能處理這些層型的解方。
高度優化專用硬體加速器的問題是,它們聚焦範圍很小、每個模組都被精心設計成可以妥善完成某項任務,導致有限的專用化,而這通常被理解為將硬體應用限制在為其所設計的領域中。
精簡操作集運算(ROSC)是Imagination Technologies(IMG)解決此問題的方法,其來自對包含高度偽裝通用操作集之某些硬體加速器的認識,ROSC正透過一或多個可用的固定功能構建新的操作(加速器上不存在針對這種操作的專門硬體)。
如何達到這點? 一開始並不明確,其往往需要一些創造力—硬體有時會以非正統的方式被使用!然而,隨著這些技術庫被構建來實現常見操作,重用它們來進行新操作變得越來越容易,此方法可將加速器的靈活性遠遠擴展到其主要應用之外,同時也為硬體加速器帶來RISC的許多優點,例如操作重用、通用性和編譯器的複雜性轉移,而無需新硬體。
ROSC更常規的替代方案通常如下:
• 在另一台裝置上執行這些操作,如CPU、GPU或DSP,但這並不可取,因為它會消耗系統頻寬和系統其餘部分的寶貴運算資源。
• 增加通用可編程單元,如微處理器在內建或旁置的設計,這增加了原來缺少的功能,但也增加了硬體複雜性以及電源和面積的消耗,與固定功能硬體相比,此類硬體的運算密度(單位面積的操作數)通常較低。
• 在為每個缺失的層型添加更多專用硬體模塊,雖然這實現了高度優化新模組,但它使架構處於不斷追趕最新技術的狀態(即它不能因應未來需求),還會導致硬體膨脹和暗矽問題。
以上所有缺點,如增加面積和功耗或消耗CPU時間和頻寬等系統資源,相較之下ROSC提供一種更優雅的方式,其復用既有的固定功能硬體於常見的神經網路操作,以支援廣泛的其他層型。
使用ROSC構建複雜層
如下所示,softmax可透過硬體支援操作構建,在這種情況下,目標架構是IMG Series4 NNA(IMG 4系列NNA)。
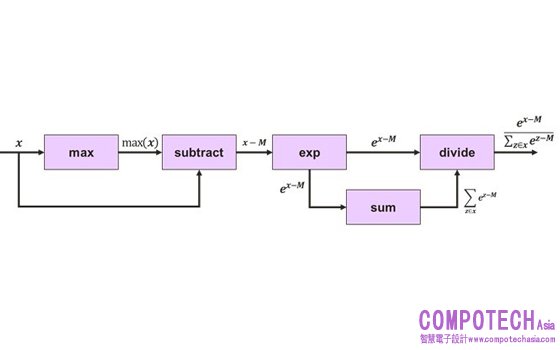
• 一個1×1的卷積其中權重全部為1可以用來實現跨通道的求和。
• 除法可以一個張量與另一個張量的倒數相乘來實現,Series4的LRN(本地響應規範化)模組可設定為計算倒數。
• 跨通道最大值可以透過將Channel方向轉至空間軸上,並執行一系列空間最大池化操作來實現,之後再轉回Channel方向。
• 由於指數僅限於負值和零輸入值,啟動LUT可以設定為指數衰減函數。
不適用固定硬體的常用模式一般會降低利用率,不過將數據保留在裝置上的收益通常大於這個缺點,假設在上述softmax建置中,我們僅實現4核IMG 4系列NNA的1%的利用率,該NNA 全速時具有40 TOPS,因此即使在1% 的利用率下仍然以非常可觀的400 GOPS運作,晶片上記憶體的可用性結合Imagination 的tensor tiling演算法意味著中間數據可以保留在本地,以將頻寬消耗降至最低。最終我們避免了需要輔助處理器來執行此層,並且不需要佔用主機CPU 時間,ROSC有利於代碼重用,例如:一旦我們為Softmax 生成用於除法和跨通道最大值的建置,便可在其他層中重複使用這些建置,例如規範化操作,它重用softmax的除法建置,平方根操作也透過LRN 模組建置,全局平均值減使用的技巧與我們在softmax中用於全局最大值減的技巧相同。
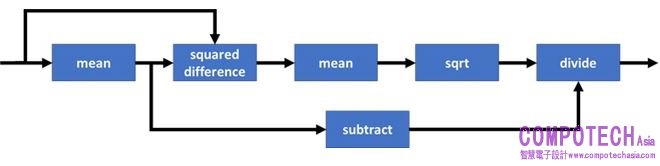
不難看出,如何以這種方式構建可重複使用的底層構建庫,從而使實現新的層型變得越來越簡單,這就是我們如何使用ROSC實現因應未來技術的方法,ROSC 還自然地適用於現有的圖向下編譯器(如Glow 和TVM),在其中我們可將高級層分解為上圖所示的運算圖,並透過由原始神經網路操作組成的子圖依次替換每個部分。
在由一小部分複雜操作(如神經網路推理)主導的應用程式中,使用固定功能硬體使運算密度最大化,產生CISC處理器,而發現其功能覆蓋範圍極其有限,但是我們可以重新分配專用的NNA硬體(在我們的例子中是IMG 4系列),以覆蓋範圍極廣的層型。
以這種高度非正統的方式使用硬體往往會降低利用率。然而,只有少部分工作負載需要採用這種方式,我們發現,隨著整體性能提高,其往往是一個值得付出的代價,並且同時可減少頻寬和功率,特別是當 NNA 與典型的 SoC 中其他可用裝置相比時具有如此強大的運算能力。






