
訓練生成式人工智慧(GenAI)神經網路模型通常需要花費數月的時間,數千個基於GPU並包含數十億個電晶體的處理器、高寬頻SDRAM和每秒數太比特的光網路交換機要同時連續運行。雖然人工智慧有望帶來人類生產力的飛躍,但其運行時能耗巨大,所以導致溫室氣體的排放也顯著增加。
據《紐約時報》報導,到2027年,人工智慧伺服器每年的用電量將達到85至134太瓦時(terawatt),大致相當於阿根廷一年的用電量。
為了應對日益加劇的能耗挑戰,AI處理器的供電網路經歷了多代的進化。這種全面的演進發展涉及電路架構、電源轉換拓撲、材料科學、封裝和機械/熱工程方面的創新。
生成式人工智慧訓練處理器的供電方案負載點模式和分比式模式的進化:
從2020年到2022年,熱設計功率(TDP)幾乎翻了一番,從400W增加到了700W。TDP指標是指生成式人工智慧訓練應用中GPU引擎的連續功耗。自2022年起,半導體行業的TDP水準不斷攀升,到了2024年3月,市場上甚至出現了一款TDP高達1000W的GPU。

圖1:基於GPU的生成式人工智慧訓練處理器晶片複合體,加速器模組(AM)上安裝有高寬頻記憶體(HBM)
用於生成式人工智慧訓練的小晶片(chiplet)處理器複合體集成了一個GPU或ASIC晶片,以及六到八個高寬頻記憶體(HBM)晶片。採用4奈米CMOS 工藝的GPU通常以0.65V的內核VDD運行,可能包含1000億或更多的電晶體。HBM提供144GB的存儲容量,其工作電壓一般為1.1V或1.2V。該處理器的一個關鍵供電特性與人工神經網路演算法負載有關。對比處於空閒狀態的GPU和演算法滿載狀態的GPU,瞬態電流消耗(dI/dt)差別可能非常大,可能達到每微秒2000安培或更多。此外,該處理器不能容忍較大的電源電壓下沖或過沖幅值;這些負載階躍瞬變必須限制在標稱VDD的10%以內。設計用於生成式人工智慧訓練處理器的供電解決方案時,由於這些動態操作條件的原因,峰值電流輸送能力通常設計為連續電流輸送能力的兩倍,峰值事件通常持續數十毫秒(圖1)。
對於CPU、FPGA、網路交換機處理器以及現在的AI訓練和推理晶片發展最重要的供電架構是負載點(PoL)方法。相較於傳統的多相並聯電源架構,分比式PoL電源架構實現了更高的功率和電流密度。這種電源架構借鑒了理想變壓器的“匝數比”概念,通過分壓實現電流倍增。電流倍增的可擴展性使我們能夠根據不同的輸出電壓和電流需求,開發一系列全面的PoL轉換器。這對客戶來說至關重要,因為高級AI訓練處理器的需求正快速變化。
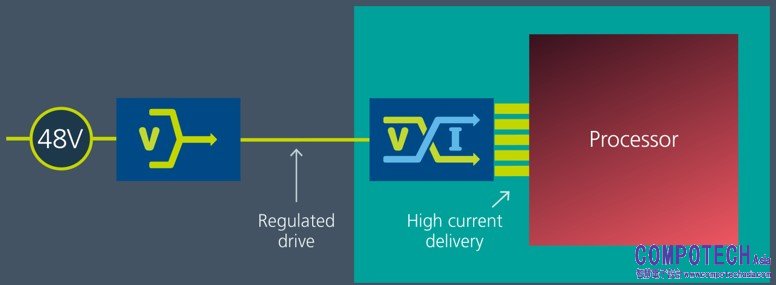
圖2:分比式電源架構可以提供超過1000安培的大電流,並使供電網路的阻抗降低20倍
分比式電源架構(FPA)——分解為穩壓和變壓兩部分功能
生成式人工智慧電源系統設計面臨的主要挑戰包括:
• 很高的電流輸送能力,範圍從500安培到2000安培
• 負載需要出色的動態響應
• 巨大的PDN損耗和阻抗
• 48V母線基礎架構的標準化使用,需要從48V轉換到1V以下的能力
要解決這種大電流和高密度負載點(PoL)問題,需要採用不同的方法。先進的分比式電源架構將穩壓和變壓/電流倍增功能進行了分解,可將這些供電級放置在最佳位置,從而達到最高的效率和功率/電流密度。
當輸入電壓(VIN)等於輸出電壓(VOUT)時,穩壓器的效率最高,隨著輸入輸出比的增加,效率逐漸降低。在36至60V的典型輸入電壓範圍內,最佳輸出母線電壓將是48V,而不是中繼母線架構(IBA)中常見的傳統12V母線電壓。48V輸出母線所需的電流是12V母線的四分之一(P=VI),而PDN的損耗是電流的平方(P = I2R),這意味著損耗降低至原來的 1/16。因此,先安裝穩壓器並將其調節至48V輸出,可以實現最高的效率。穩壓器還必須接受有時低於48V的輸入電壓,這就需要一個降壓-升壓的功能來滿足這一設計需求。一旦輸入電壓得到了穩壓,下一步便是將48V轉換為1V。
在需要為1V負載供電的情況下,最佳變壓比為48:1。在這種情況下,穩壓器將輸入電壓降壓或升壓到48V輸出,再由變壓器將電壓從48降至1V。降壓變壓器以相同的比率加大電流,因此變壓器元件也可以稱為電流倍增器。在這種情況下,1安培的輸入電流將倍增至48安培的輸出電流。為了最大限度地減少大電流輸出的PDN損耗,電流倍增器必須小巧,以便盡可能靠近負載放置。
PRM穩壓器和VTM/MCM模組化電流倍增器結合在一起,構成Vicor分比式電源架構。這兩個器件相互合作,各司其職,實現完整的DC-DC轉換功能。
PRM通過調製未穩壓的輸入電源提供穩壓輸出電壓,即“分比式母線電壓”。該母線供電給VTM,由VTM將分比式母線電壓轉換為負載所需的電平。
與IBA不同,FPA不通過串聯電感器從中繼母線電壓降壓至PoL。FPA不通過降低中間母線電壓來平均電壓,而是使用電流增益為1:48或更高的高壓穩壓和電流倍增器模組,以提供更高的效率、更小的尺寸、更快的回應和1000安培及以上的可擴展性(圖2)。
垂直放置PoL轉換器減少功耗耗散
在前幾代大電流生成式人工智慧處理器電源架構中,PoL轉換器被放在處理器複合體的橫向(旁邊)位置。由於銅的電阻率和PCB上的走線長度,橫向放置的PoL供電網路(PDN)的集總阻抗相當高,可能達到200μΩ或更高。隨著生成式人工智慧訓練處理器的連續電流需求增加到1000安培,這意味著PCB本身就會消耗掉200瓦的功率。考慮到在AI超級電腦中用於大型語言模型訓練的加速器模組(AM)多達數千個,而且幾乎從不斷電,通常會持續運行10年或更長時間,這200瓦的功率損耗在整體上變得非常龐大。
認識到這種能源浪費後,AI電腦設計師已經開始評估採用垂直供電(VPD)結構,將PoL轉換器直接放置在處理器複合體的下方。在垂直供電網路中,集總阻抗可能降至10μΩ或更低,這意味著在內核電壓域1000安培的連續電流下,只會消耗10瓦的功率。也就是說,通過將PoL轉換器從橫向放置改為縱向放置,PCB的功耗減少了200–10=190瓦(WPCB )(圖3)。
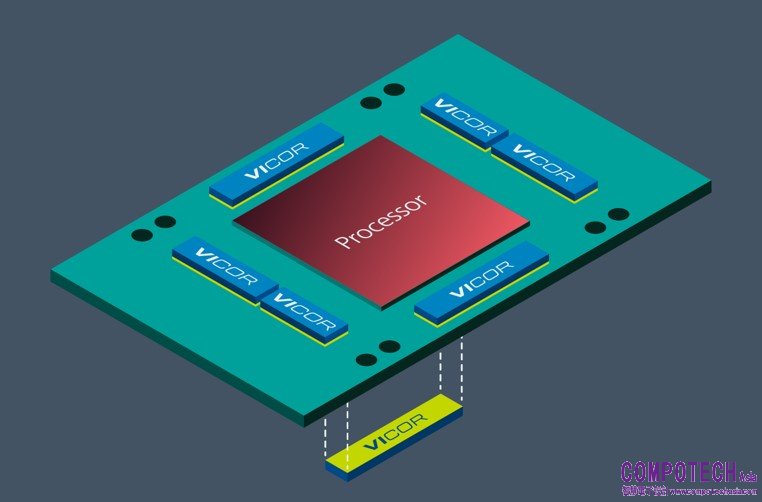
圖3 生成式人工智慧加速模組從橫向(頂部)供電改為縱向(背部)供電,可將PDN損耗降低至1/20
VPD的另一個優點是降低了GPU晶片表面電壓梯度,這也有助於節省電力。如前所述,典型的4奈米CMOS GPU的標稱工作電壓為0.65VDD。使用橫向供電時,將電源提供給處理器複合體的四邊,由於積體電路的配電阻抗較高(通常使用電阻率高於銅的鋁導體),可能需要0.70V的電壓,才能確保GPU晶片中心的電壓達到標稱值0.65V。而採用縱向供電時,可以確保整個晶片表面的電壓為0.65V。0.70–0.65=50 mV,這個差值乘以1000安培,可額外節省50瓦(WVDD)的功率。在本例中,節省的總功率為190 WPCB + 50 WVDD = 240瓦(圖4)。
根據未來幾年公共領域對加速器模組(AM)需求的預測(2024年超過250萬件),以及對電力成本的合理估計(每兆瓦時75美元),每個AM節省240W電力,到2026年將在全球範圍內實現太瓦時的電力節省,相當於每年節約數十億美元的電力營運成本,而且根據可再生能源的使用比例,每年還能永久性地減少數百萬噸的二氧化碳排放。
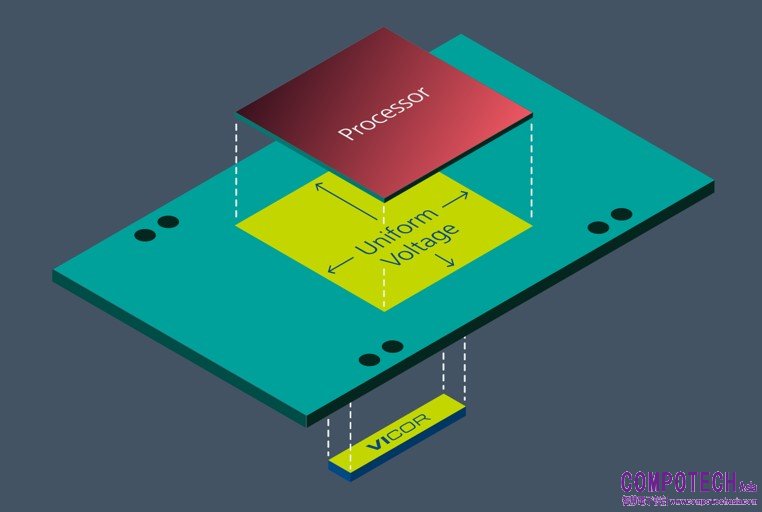
圖4:使用VPD時,處理器晶片的表面電壓均勻,有助於最大限度地提高計算效能,同時最小化功率損耗
遏制失控的生成式人工智慧功耗
Vicor正引領生成式人工智慧供電技術的創新浪潮。他們提供的分比式負載點轉換器解決方案有助於提升生成式人工智慧處理器的功效,使生成式人工智慧的功耗與社會層面的環境保護和節能目標相一致。
Vicor持續推動電源架構的創新,並開發先進的新產品,致力於解決生成式人工智慧模型訓練帶來的功耗增加問題。通過採用先進的分比式電流倍增器方法進行負載點DC-DC轉換,就可以充分發揮生成式人工智慧優勢,同時有效控制全球範圍內的能源消耗。






